6 Week 5- Finishing Variant Calling, then a pivot to R!
Picking up from last week, we will start where we left off with a variant calling pipeline. Then we’ll pivot to interacting with the cluster in a new way, by starting RStudio sessions in OnDemand.
6.1 Main Objectives
- Organize simple commands into scripts to execute a variant calling pipeline
- Write code in Rstudio through FarmOnDemand
- Understand the different parts of the Rstudio window
- Create and modify objects in R and general R operation
6.2 Warmup Part 1: Comparing scripts with a friend
Buddy up! Start an OnDemand session and navigate to the script that you wrote for the week 4 assignment.
If either you or your partner’s script did not run, take some time to look at the
code together! Try to fix any errors and get it to run. If you’re having
trouble diagnosing your issues, remember that you can look at your log files, which
have the extensions .err and /out.
If both of your code produced the expected files, compare scripts! Find any places where your code differs, and discuss why you chose to code it the way you did! After seeing your partner’s script, are there any changes you’d like to make to yours?
6.3 Warmup Part 2: Ensuring we have well organized data!
Last week’s assignment was to rerun the fastqc and cutadapt commands that
we learned last week to create a well organized file system. If your script
didn’t work exactly as you planned, let’s make sure that we
all are moving forward into the next section with the same files.
From within your week4 folder, you should make sure you have a folder called
raw_data which contains the following files:
$ ls raw_data
Ppar_tinygenome.fna.gz SRR6805881.tiny.fastq.gz SRR6805883.tiny.fastq.gz SRR6805885.tiny.fastq.gz
SRR6805880.tiny.fastq.gz SRR6805882.tiny.fastq.gz SRR6805884.tiny.fastq.gzFrom within your week4 folder, you should make sure you have a folder called
trimmed_fastqs which contains the following files:
$ ls trimmed_fastqs
SRR6805880.tiny_trimmed.fastq.gz SRR6805882.tiny_trimmed.fastq.gz SRR6805884.tiny_trimmed.fastq.gz
SRR6805881.tiny_trimmed.fastq.gz SRR6805883.tiny_trimmed.fastq.gz SRR6805885.tiny_trimmed.fastq.gzYou may have some additional files inside your folder, like fastqc files, your week 4 scripts or slurm outputs, those can all stay there!
If you are struggling to get the files into the right folder, you can copy this folder
into your personal week4 folder from the folder week4_files as follows:
$ cd /group/rbaygroup/eve198-genomics/yourdirectory/week4
$ cp -r /group/rbaygroup/eve198-genomics/week4_files/raw_data ./
$ cp -r /group/rbaygroup/eve198-genomics/week4_files/trimmed_fastqs ./Rerun the ls commands to ensure that you have everything you need in the
raw_data and trimmed_fastqs. Now we can move forward with the next steps in
the variant calling pipeline!
6.4 Step 3: Building an index of our genome
Recall that we’ve already performed QC and adapter cutting on our sequencing reads.
Today, we’ll pick up where we left off with our variant calling pipeline:
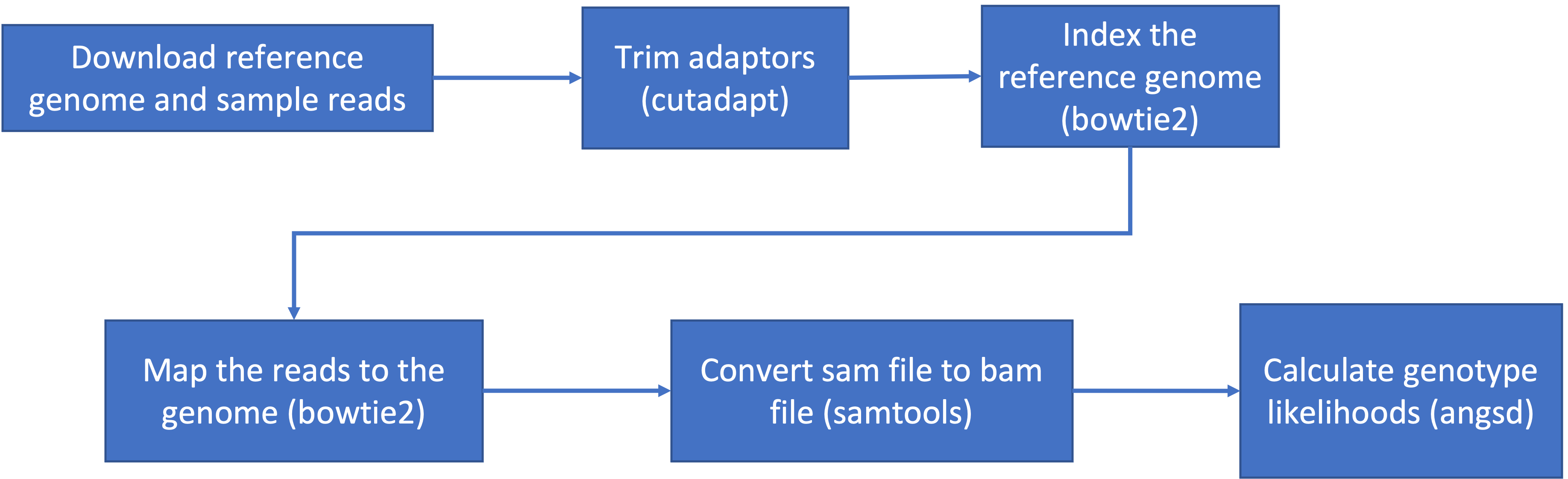
Recall that we need to reload packages every time we open a new OnDemand session. This week we’ll need:
- samtools: allows us to filter and view our mapped data
- bowtie2: to map our reads to the reference genome
- angsd: used to find variants in our data
Load all these packages using module load.
Our next task is to index our genome. We’ll do that with the bowtie2-build command. This will generate a lot of files that describe different aspects of our genome
We give bowtie2-build two things, the name of our genome, and a general name to label the output files. I always keep the name of the output files the same as the original genome file (without the .fna.gz extension) to avoid confusion.
bowtie2-build raw_data/Ppar_tinygenome.fna.gz raw_data/Ppar_tinygenomeThis should produce several output files with extensions including: .bt2 and rev.1.bt2 etc (six files in total)
6.5 Step 4: Map reads to the genome
Now that we’ve indexed our reference, we can map our sequencing reads to that reference genome. Let’s map those reads using a for loop.
First, let’s set up a directory for the output files, which will have the extension
.sam (more on that later!)
$ mkdir samsfor filename in trimmed_fastqs/*.tiny_trimmed.fastq.gz
do
base=$(basename $filename .tiny_trimmed.fastq.gz)
echo ${base}
bowtie2 -x raw_data/Ppar_tinygenome -U trimmed_fastqs/${base}.tiny_trimmed.fastq.gz -S sams/${base}.sam
doneYou should see a bunch of text telling you all about how well our reads mapped to the genome. For this example we’re getting a low percentage (~20%) because of how the genome and reads were subset for this exercise.
You’ll also notice that we have made a bunch of .sam files. THis stands
for Sequence Alignment Map file. Let’s use less to look at one of
these files using less
6.6 Step 5: sam to bam file conversion
The next step is to convert our sam file to a bam (Binary Alignment Map file). This gets our file ready to be read by angsd the program we’re going to use to call SNPs.
mkdir bams
for filename in sams/*.sam
do
base=$(basename $filename .sam)
echo ${base}
samtools view -bhS sams/${base}.sam | samtools sort -o bams/${base}.bam
done6.7 Step 6: Genotype likelihoods
There are many ways and many programs that call genotypes. The program that we will use calculates genotype likelihoods, which account for uncertainty due to sequencing errors and/or mapping errors and is one of several programs in the package ANGSD. The purpose of this class is not to discuss which program is the “best”, but to teach you to use some commonly used programs.
angsd needs a text file with the .bam file names listed. We can make
that by running the command below
ls bams/*.bam > bam.filelistLook at the list:
cat bam.filelistRun the following code to calculate genotype likelihoods
angsd -bam bam.filelist -GL 1 -out genotype_likelihoods -doMaf 2 -SNP_pval 1e-2 -doMajorMinor 1The output of angsd gives us a nice overview of what happened:
-> Output filenames:
->"genotype_likelihoods.arg"
->"genotype_likelihoods.mafs.gz"
-> Tue Feb 3 22:27:17 2026
-> Arguments and parameters for all analysis are located in .arg file
-> Total number of sites analyzed: 71450
-> Number of sites retained after filtering: 9
[ALL done] cpu-time used = 1.39 sec
[ALL done] walltime used = 1.00 secWe can see that it generated two files, one with a .arg extension (which has a record of the script we ran to generate the output), and a .maf file (that will give you the minor allele frequencies and is the main output file). We can also see that we started with 71,450 sites but only retained 9 after filtering.
To see what the other parameters do you can run the following:
angsd -hWe can change the parameters of the angsd genotype likelihoods command
by altering the values next to -SNP_pval. If we remove the -SNP_pval
command entirely we get around 70,000 sites retained! Wow! That seems like a
lot given our ~20% mapping rate. If you instead increase the p-value
threshold to 1e-3 we find 3 SNPs.
Class Exercise 1: Changing angsd parameters
To see what the parameters you can use with angsd, type
angsd -hTry changing the value of-SNP_pvaland rerunning angsd. How many sites are retained if we remove the-SNP_pvalflag entirely? How many sites are retained if you instead increase the p-value threshold to 1e-3?
6.8 Orientation to R
There are many R packages that are built to work with SNP data! So often, once we use slurm scripts to pare down our data from sequencing reads to SNPs, we read the SNP data into R to analyze it from there! Before we get to working with SNP data, we’ll start with a more general intro to R.
This lesson is modified from materials compiled by Serena Caplins from the STEMinist_R lessons produced by several UC Davis graduate student and which can be found here.
First let’s navigate to our R studio on Farm OnDemand! Launch your
session with the information shown below:
Give yourself 2 for memory and make sure your conda environment is set to r-4.4.2
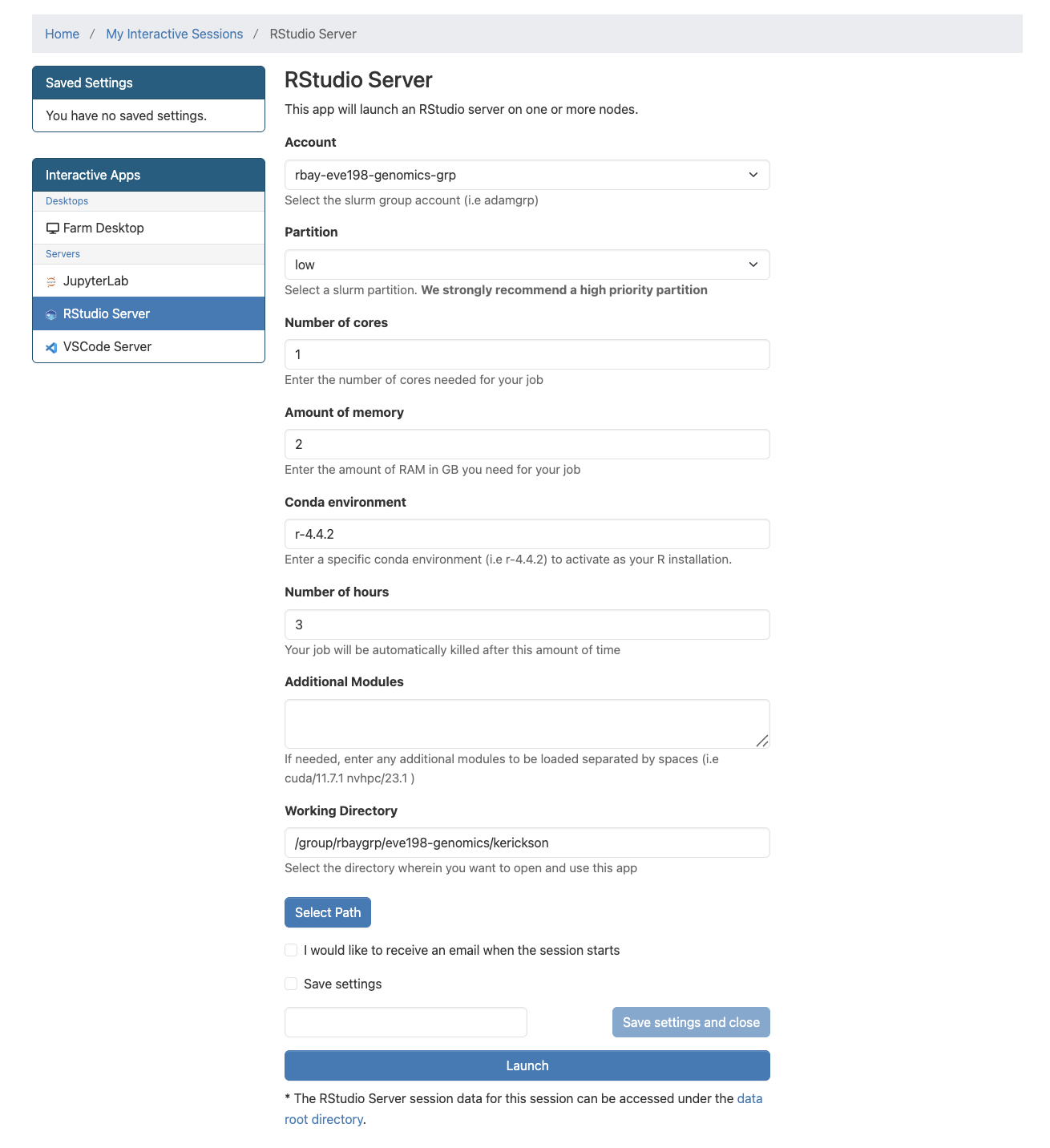
Fill out this information
After we start it up we will want to create a new file called “Week5-IntroR.R” to type our scripts for today.
To do this, we will click File, New File then R script. Name your
file with your name-Week5-introR
# before a sentence comments out what you want before you write code.
Without a # R will think what you are writing needs to be run as a
command! I have used comments in this example to write what the script is for. The top left is the script, the bottom left is the terminal window where code and outputs will be typed, the top right is your environment
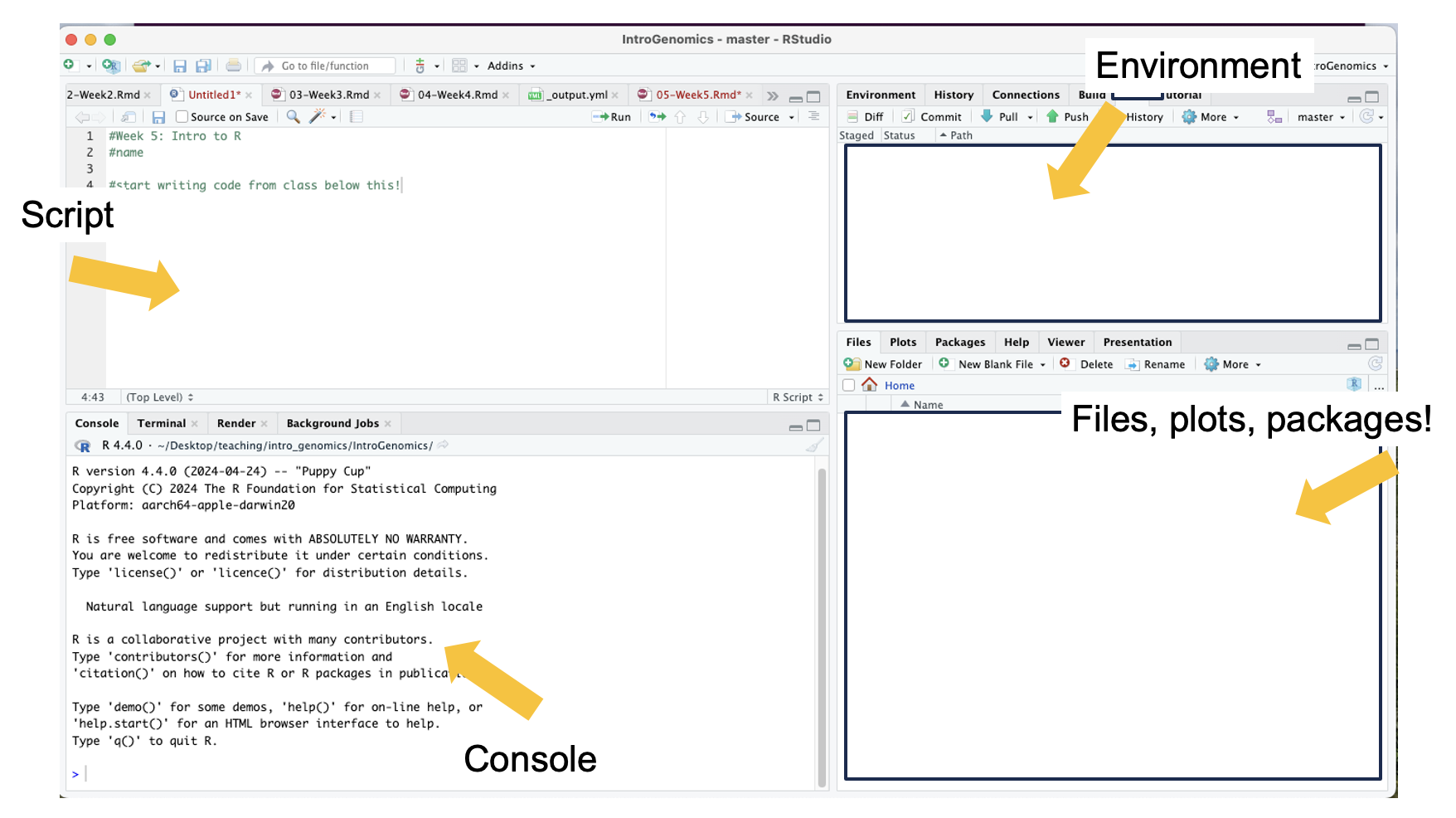 R can be used for basic arithmetic. Type this into your script and hit
enter:
R can be used for basic arithmetic. Type this into your script and hit
enter:
#adding prompt
5+10+23## [1] 38It can also store values in variables:
You can assign an object using an assignment operator <- or =.
#storing variables
number<-10
numbers<-c(10, 11, 12, 14, 16)You can see your assigned object by typing the name you gave it.
#assigned objects
number## [1] 10numbers## [1] 10 11 12 14 16Objects can be numbers or characters:
#objects as characters
cat<-"meow"
dog<-"woof"We can use colons to get sequences of numbers:
#sequence of numbers
n<-1:100Data Structures include:
Vector
Lists
Matrices
Factor
Data frame
Vectors can also include characters (in quotes): c()=concatenate, aka
link things together!
#link things together with this code
animals<-c("woof", "meow", "hiss", "baa")6.9 Manipulating a vector object
We can get summaries of vectors with summary()
#summarize what you have done so far
summary(n)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.00 25.75 50.50 50.50 75.25 100.00We can see how long a vector is with length()
#how long is vector n
length(n)## [1] 100You can use square brackets [] to get parts of vectors.
#what is the 50th entry in our vector n?
n[50]## [1] 50Class Exercise 2
- What is the 2nd entry in our vector animals?
create a new vector with the following code for different field sites to answer questions 2 & 3:
site_code <- c("BB","ShC","BH","Pes","StC","MR","PV","KH","CM","RP","Car","SR","RM","Dav","JB","Mal","PB","PA","Leu","VD","A")
- Without counting, which site is the 10th entry?
- How many sites are there total?
6.10 Operations act on each element of a vector
# +2
numbers+2## [1] 12 13 14 16 18# *2
numbers*2## [1] 20 22 24 28 32# mean
mean(numbers)## [1] 12.6# ^2
numbers^2## [1] 100 121 144 196 256# sum
sum(numbers)## [1] 636.11 Operations can also work with two vectors
#define a new object y
y<-numbers*2
# n + y
numbers + y## [1] 30 33 36 42 48# n * y
numbers * y## [1] 200 242 288 392 5126.12 A few tips below for working with objects
We can keep track of what objects R is using, with the functions ls()
and objects()
ls()## [1] "animals" "cat" "dog" "n" "number" "numbers"
## [7] "site_code" "y"objects() #returns the same results as ls() in this case. because we only have objects in our environment.## [1] "animals" "cat" "dog" "n" "number" "numbers"
## [7] "site_code" "y"This is where those objects show up with you type ls(): 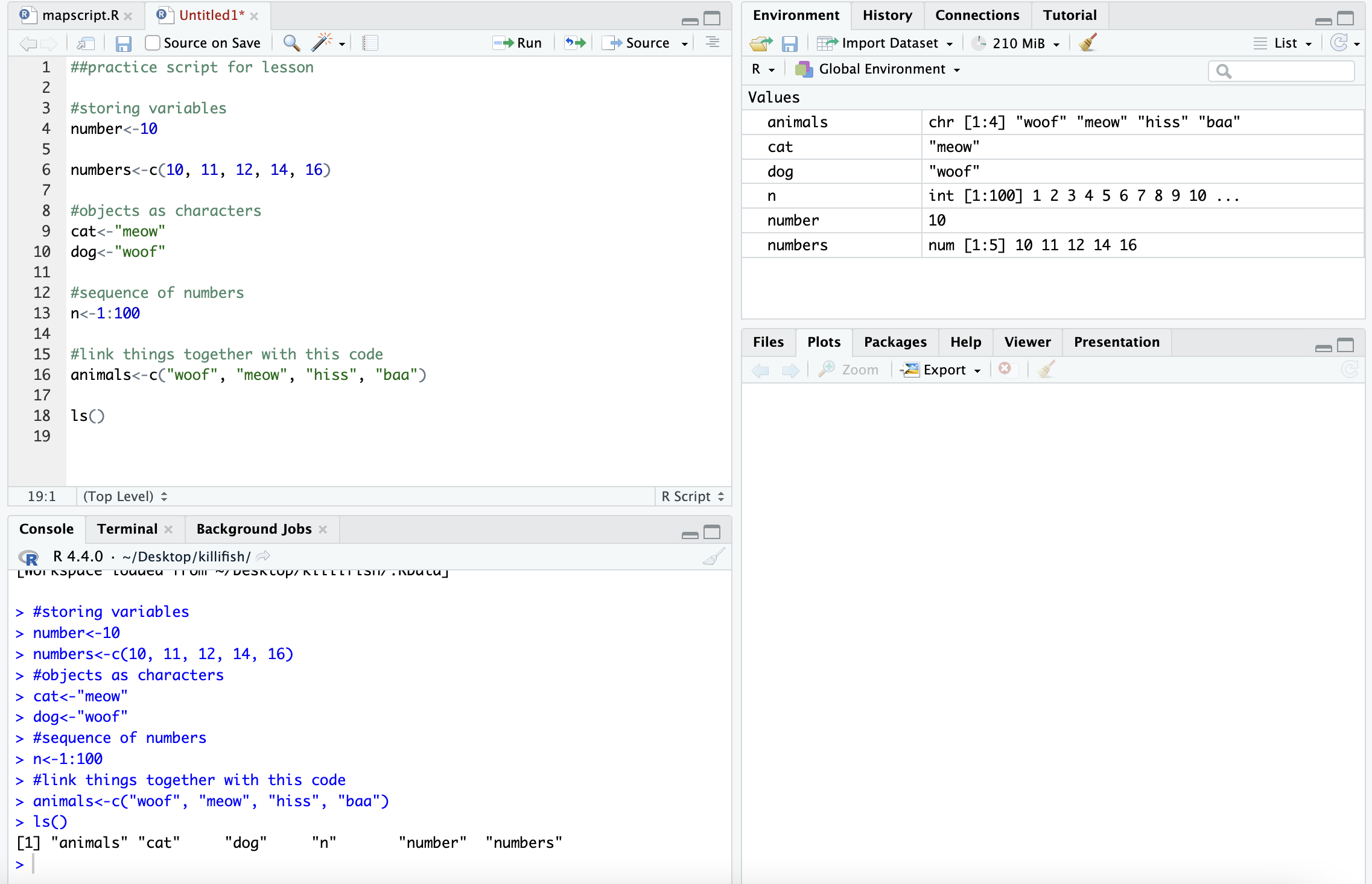
# how to get help for a function; you can also write help()
?ls
# you can get rid of objects you don't want
rm(numbers)
# and make sure it got rid of them
ls()## [1] "animals" "cat" "dog" "n" "number" "site_code"
## [7] "y"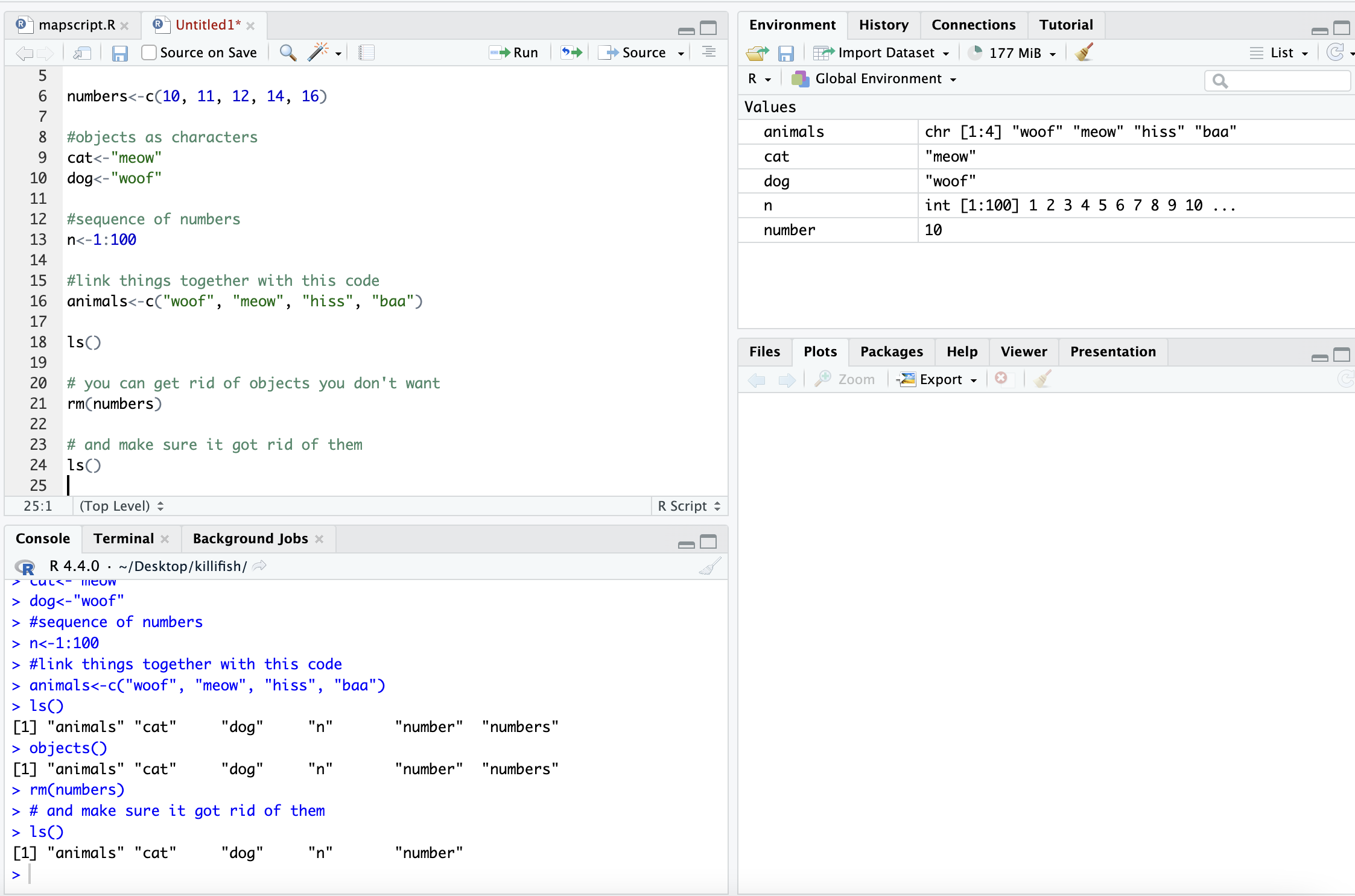
After removal
Call the help files for the functions ls() and rm() + What are the arguments for the ls() function? + What does the ‘sorted’ argument do?
From the help file: sorted is a logical indicating if the resulting character should be sorted alphabetically. Note that this is part of ls() may take most of the time.
6.13 Characterizing a dataframe
We’ll now move from working with objects and vectors to working with dataframes:
- Here are a few useful functions! I will go over each as we introduce
them throughout the lesson today:
- install.packages()
- library()
- data()
- str()
- dim()
- colnames() and rownames()
- class()
- as.factor()
- as.numeric()
- unique()
- t()
- max(), min(), mean() and summary()
We’re going to use data on sleep patterns in mammals. This requires installing a package (ggplot2) and loading the data
Install the package ggplot2. This only has to be done once and after
installation we should then comment out the command to install the
package with a #.
#install.packages("ggplot2")
#load the package
library (ggplot2)## Warning: package 'ggplot2' was built under R version 4.4.3Load the data (it’s called msleep). This dataset includes information bout mammal sleep times and weights that was taken from a study by V. M. Savage and G. B. West. “A quantitative, theoretical framework for understanding mammalian sleep. Proceedings of the National Academy of Sciences, 104 (3):1051-1056, 2007.”
The data includes
- name (common name)
- genus
- vore (carnivore, omnivore, etc)
- order
- conservation (status)
- sleep_total (total amount of sleep in hours)
- sleep_rem (rem sleep in hours)
- sleep_cycle (length of sleep cycle, in hours)
- awake (amount of time spent awake, in hours)
- brainwt (brain weight in kilograms)
- bodywt (body weight in kilograms)
data("msleep")There are many functions in R that allow us to get an idea of what the data looks like. For example, what are it’s dimensions (how many rows and columns)?
# head() -look at the beginning of the data file
# tail() -look at the end of the data file
head(msleep)## # A tibble: 6 × 11
## name genus vore order conservation sleep_total sleep_rem sleep_cycle awake
## <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Cheetah Acin… carni Carn… lc 12.1 NA NA 11.9
## 2 Owl mo… Aotus omni Prim… <NA> 17 1.8 NA 7
## 3 Mounta… Aplo… herbi Rode… nt 14.4 2.4 NA 9.6
## 4 Greate… Blar… omni Sori… lc 14.9 2.3 0.133 9.1
## 5 Cow Bos herbi Arti… domesticated 4 0.7 0.667 20
## 6 Three-… Brad… herbi Pilo… <NA> 14.4 2.2 0.767 9.6
## # ℹ 2 more variables: brainwt <dbl>, bodywt <dbl>tail(msleep)## # A tibble: 6 × 11
## name genus vore order conservation sleep_total sleep_rem sleep_cycle awake
## <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Tenrec Tenr… omni Afro… <NA> 15.6 2.3 NA 8.4
## 2 Tree s… Tupa… omni Scan… <NA> 8.9 2.6 0.233 15.1
## 3 Bottle… Turs… carni Ceta… <NA> 5.2 NA NA 18.8
## 4 Genet Gene… carni Carn… <NA> 6.3 1.3 NA 17.7
## 5 Arctic… Vulp… carni Carn… <NA> 12.5 NA NA 11.5
## 6 Red fox Vulp… carni Carn… <NA> 9.8 2.4 0.35 14.2
## # ℹ 2 more variables: brainwt <dbl>, bodywt <dbl># str()
str(msleep)## tibble [83 × 11] (S3: tbl_df/tbl/data.frame)
## $ name : chr [1:83] "Cheetah" "Owl monkey" "Mountain beaver" "Greater short-tailed shrew" ...
## $ genus : chr [1:83] "Acinonyx" "Aotus" "Aplodontia" "Blarina" ...
## $ vore : chr [1:83] "carni" "omni" "herbi" "omni" ...
## $ order : chr [1:83] "Carnivora" "Primates" "Rodentia" "Soricomorpha" ...
## $ conservation: chr [1:83] "lc" NA "nt" "lc" ...
## $ sleep_total : num [1:83] 12.1 17 14.4 14.9 4 14.4 8.7 7 10.1 3 ...
## $ sleep_rem : num [1:83] NA 1.8 2.4 2.3 0.7 2.2 1.4 NA 2.9 NA ...
## $ sleep_cycle : num [1:83] NA NA NA 0.133 0.667 ...
## $ awake : num [1:83] 11.9 7 9.6 9.1 20 9.6 15.3 17 13.9 21 ...
## $ brainwt : num [1:83] NA 0.0155 NA 0.00029 0.423 NA NA NA 0.07 0.0982 ...
## $ bodywt : num [1:83] 50 0.48 1.35 0.019 600 ...dim(), ncol(), nrow()- dimensions, number of columns, number of rows colnames(), rownames() - column names, row names
Rstudio also allows us to just look into the data file with View().
Try to look at the msleep data using View(msleep)
6.14 How to access parts of the data
We can also look at a single column at a time. There are three ways to access this: $, [,#] or [,“a”].
Think about “Remote Control car” to remember that [5,] means fifth row and [,5] means fifth column! Rows are listed first and columns are listed second.
Each way has it’s own advantages! The first subsets the third column of
data, so you need to know where your data of interest is. The second
subsets the vore column only. The third prints all of the data from
the vore column in your console window.
msleep[,3]## # A tibble: 83 × 1
## vore
## <chr>
## 1 carni
## 2 omni
## 3 herbi
## 4 omni
## 5 herbi
## 6 herbi
## 7 carni
## 8 <NA>
## 9 carni
## 10 herbi
## # ℹ 73 more rowsmsleep[, "vore"]## # A tibble: 83 × 1
## vore
## <chr>
## 1 carni
## 2 omni
## 3 herbi
## 4 omni
## 5 herbi
## 6 herbi
## 7 carni
## 8 <NA>
## 9 carni
## 10 herbi
## # ℹ 73 more rowsmsleep$vore## [1] "carni" "omni" "herbi" "omni" "herbi" "herbi" "carni"
## [8] NA "carni" "herbi" "herbi" "herbi" "omni" "herbi"
## [15] "omni" "omni" "omni" "carni" "herbi" "omni" "herbi"
## [22] "insecti" "herbi" "herbi" "omni" "omni" "herbi" "carni"
## [29] "omni" "herbi" "carni" "carni" "herbi" "omni" "herbi"
## [36] "herbi" "carni" "omni" "herbi" "herbi" "herbi" "herbi"
## [43] "insecti" "herbi" "carni" "herbi" "carni" "herbi" "herbi"
## [50] "omni" "carni" "carni" "carni" "omni" NA "omni"
## [57] NA NA "carni" "carni" "herbi" "insecti" NA
## [64] "herbi" "omni" "omni" "insecti" "herbi" NA "herbi"
## [71] "herbi" "herbi" NA "omni" "insecti" "herbi" "herbi"
## [78] "omni" "omni" "carni" "carni" "carni" "carni"If you wanted to save these as objects, you need to add an arrow an a new name for that object. They should all be the same!
column3<-msleep[,3]
voreonly<-msleep[, "vore"]
vores<-msleep$vore
head(column3) #do this or View() for all of your new objects!## # A tibble: 6 × 1
## vore
## <chr>
## 1 carni
## 2 omni
## 3 herbi
## 4 omni
## 5 herbi
## 6 herbiIt’s important to know the class of data if you want to manipulate it.
For example, you can’t add characters. msleep contains several
different types of data. We see with str() that there are columns of
data that are characters and numeric.
Data Types/Classes:
Character (names)
Numeric (numbers)
Logical (T/F)
Integer (2L for example)
Complex (imaginary #s)
Raw (not really used)
class(msleep$vore) #character!## [1] "character"class(msleep$sleep_total) #numeric!## [1] "numeric"We can also look at a single row at a time. There are two ways to access this:
- by indicating the row number in square brackets next to the
name of the dataframe
name[#,] - by calling the actual name of the row (if your rows have names)
name["a",].
msleep[43,]## # A tibble: 1 × 11
## name genus vore order conservation sleep_total sleep_rem sleep_cycle awake
## <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Little… Myot… inse… Chir… <NA> 19.9 2 0.2 4.1
## # ℹ 2 more variables: brainwt <dbl>, bodywt <dbl>msleep[msleep$name == "Mountain beaver",]## # A tibble: 1 × 11
## name genus vore order conservation sleep_total sleep_rem sleep_cycle awake
## <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Mounta… Aplo… herbi Rode… nt 14.4 2.4 NA 9.6
## # ℹ 2 more variables: brainwt <dbl>, bodywt <dbl>
We can select more than one row or column at a time:
# see two columns
msleep[,c(1, 6)]## # A tibble: 83 × 2
## name sleep_total
## <chr> <dbl>
## 1 Cheetah 12.1
## 2 Owl monkey 17
## 3 Mountain beaver 14.4
## 4 Greater short-tailed shrew 14.9
## 5 Cow 4
## 6 Three-toed sloth 14.4
## 7 Northern fur seal 8.7
## 8 Vesper mouse 7
## 9 Dog 10.1
## 10 Roe deer 3
## # ℹ 73 more rows # and make a new data frame from these subsets
subsleep<-msleep[,c(1, 6)]But what if we actually care about how many unique things are in a column?
# unique()
unique(msleep[, "order"])## # A tibble: 19 × 1
## order
## <chr>
## 1 Carnivora
## 2 Primates
## 3 Rodentia
## 4 Soricomorpha
## 5 Artiodactyla
## 6 Pilosa
## 7 Cingulata
## 8 Hyracoidea
## 9 Didelphimorphia
## 10 Proboscidea
## 11 Chiroptera
## 12 Perissodactyla
## 13 Erinaceomorpha
## 14 Cetacea
## 15 Lagomorpha
## 16 Diprotodontia
## 17 Monotremata
## 18 Afrosoricida
## 19 Scandentia # table()
table(msleep$order)##
## Afrosoricida Artiodactyla Carnivora Cetacea Chiroptera
## 1 6 12 3 2
## Cingulata Didelphimorphia Diprotodontia Erinaceomorpha Hyracoidea
## 2 2 2 2 3
## Lagomorpha Monotremata Perissodactyla Pilosa Primates
## 1 1 3 1 12
## Proboscidea Rodentia Scandentia Soricomorpha
## 2 22 1 5 # levels(), if class is factor (and if not we can make it a factor) showing the way that the data is displayed
levels(as.factor(msleep$order))## [1] "Afrosoricida" "Artiodactyla" "Carnivora" "Cetacea"
## [5] "Chiroptera" "Cingulata" "Didelphimorphia" "Diprotodontia"
## [9] "Erinaceomorpha" "Hyracoidea" "Lagomorpha" "Monotremata"
## [13] "Perissodactyla" "Pilosa" "Primates" "Proboscidea"
## [17] "Rodentia" "Scandentia" "Soricomorpha"6.15 Group Work Activity: practice exploring a dataframe

Iris Diagram for Reference
We’ll use the built-in ‘iris’ dataset. The command: `
data(iris) # this loads the 'iris' dataset. You can view more information about this dataset with help(iris) or ?iris.
This dataset was published by Ronald Fisher in his 1936 paper: “The use of multiple
measurements in taxonomic problems”. It has three plant species (setosa,
virginica, versicolor) and four morphological traits measured for each
sample in centimeters: Sepal.Length, Sepal.Width, Petal.Length and
Petal.Width. It is important to acknowledge that the field of genetics has been
built on eugenics, and Fisher was a prominent geneticist and eugenicist.
More information about this can be accessed here: https://www.ucl.ac.uk/biosciences/gee/ucl-centre-computational-biology/ronald-aylmer-fisher-1890-1962
Submit a screenshot or copied text that shows the code you ran to answer the following questions:
- How many rows are in the dataset?
- How many species of flowers are in the dataset?
- How many columns does this data frame have? What are their names?
- What class did R assign to each column?
- Create a vector that is the area of each flower’s petals. (You can assume that each petal is rectangular so that petal width * petal length = petal area)
- What is the maximum sepal length of the irises?
6.16 Key Points
- Useful functions such as
install.packages(),library()can help us upload packages and data from R, while other functions such asstr(),dim(), andunique()can help us investigate dataframes - To look at our data we can use several commands, including
view()ordata$columnofinterestif you only want to look at one variable. - Manipulating data in R can be extremely helpful in the analysis
stage, and we can get data on
mean(),min(),max(), andsummary()data on different variables of interest